
A groundbreaking study by the University at Buffalo has revealed that large language models such as ChatGPT can play a significant role in identifying deepfake images. While not yet as accurate as current detection algorithms, these models offer unique advantages, including explaining their findings in plain language. This development opens new possibilities for enhancing media forensics and combating misinformation.
In a world increasingly dominated by artificial intelligence, both in the form of text and images, the anxiety over the spread of deepfakes is substantial. However, a new study led by a research team from the University at Buffalo offers a promising avenue for turning AI against itself. This pioneering work explored whether text-generating models like ChatGPT could identify AI-generated images, known as deepfakes.
Presented at the IEEE/CVF Conference on Computer Vision & Pattern Recognition, the study found that while ChatGPT and similar large language models (LLMs) did not outperform the latest deepfake detection algorithms, their natural language processing capabilities provided a meaningful advantage.
“What sets LLMs apart from existing detection methods is the ability to explain their findings in a way that’s comprehensible to humans, like identifying an incorrect shadow or a mismatched pair of earrings,” Siwei Lyu, the study’s lead author and SUNY Empire Innovation Professor in the Department of Computer Science and Engineering within the UB School of Engineering and Applied Sciences, said in a news release. “LLMs were not designed or trained for deepfake detection, but their semantic knowledge makes them well suited for it, so we expect to see more efforts toward this application.”
The research, conducted in collaboration with the University at Albany and the Chinese University of Hong Kong, Shenzhen and supported by the National Science Foundation, underscores the critical importance of understanding how language models process images. These LLMs, trained on an extensive body of text, now also utilize large databases of captioned photos to discern the relationship between words and visuals.
“Humans do this as well. Whether it be a stop sign or a viral meme, we constantly assign a semantic description to images,” Shan Jai, the study’s first author and assistant lab director in the UB Media Forensic Lab, said in the news release. “In this way, images become their own language.”
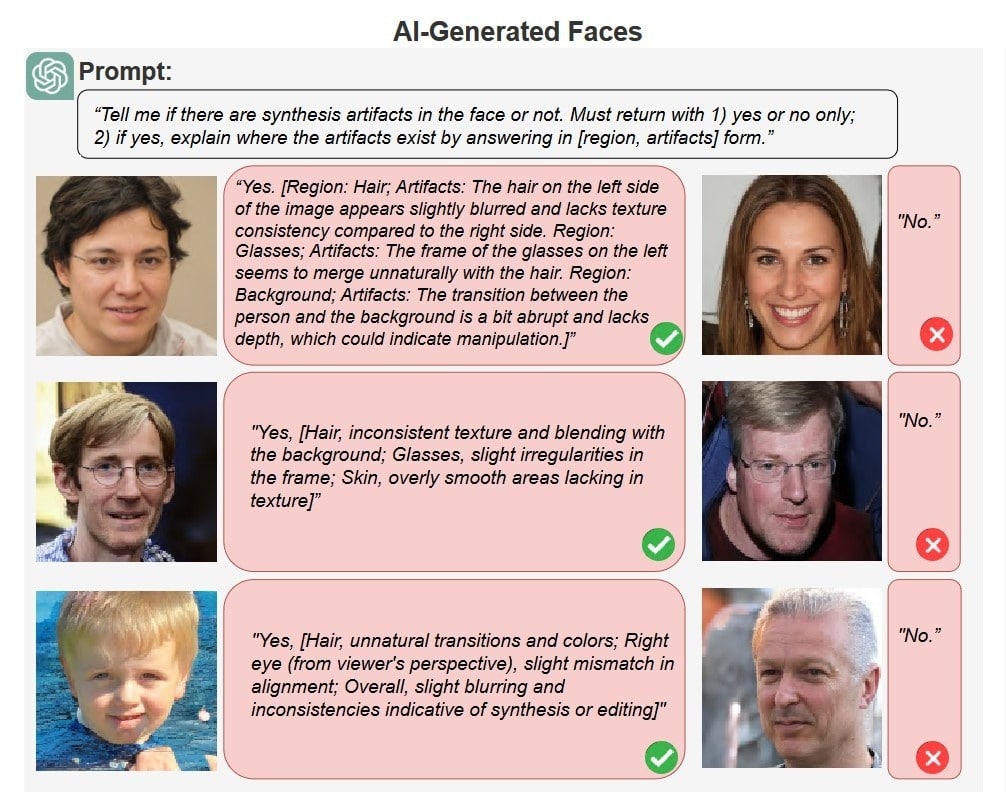
The experiment tasked GPT-4 with vision (GPT-4V) and Google’s Gemini 1.0 with distinguishing between real faces and AI-generated faces by spotting manipulations and synthetic artifacts. Despite lower accuracy compared to state-of-the-art detection models, ChatGPT achieved roughly 79.5% accuracy in identifying synthetic artifacts in images generated by latent diffusion and 77.2% in those created by StyleGAN.
“This is comparable to earlier deepfake detection methods, so with proper prompt guidance, ChatGPT can do a fairly decent job at detecting AI-generated images,” added Lyu, who also co-directs UB’s Center for Information Integrity.
A crucial advantage of ChatGPT is its ability to articulate its decision-making process in plain language. For example, when provided an AI-generated photo of a man with glasses, the model accurately noted, “the hair on the left side of the image slightly blurs” and “the transition between the person and the background is a bit abrupt and lacks depth.” This transparency makes LLMs more user-friendly.
Credit: University at Buffalo
However, ChatGPT’s performance remains below that of the leading deepfake detection algorithms, which boast accuracy rates in the mid-to-high 90s. LLMs like ChatGPT struggle to identify signal-level statistical differences often used by detection algorithms to spot AI-generated images.
“ChatGPT focused only on semantic-level abnormalities,” said Lyu. “In this way, the semantic intuitiveness of the ChatGPT’s results may actually be a double-edged sword for deepfake detection.”
Moreover, not all LLMs match ChatGPT’s effectiveness. While Gemini performed similarly in detecting synthetic artifacts, its supporting evidence was often nonsensical. Additionally, LLMs sometimes refuse to analyze images directly, stating, “Sorry, I can’t assist with that request,” when confidence levels are low.
“The model is programmed not to answer when it doesn’t reach a certain confidence level,” Lyu added. “We know that ChatGPT has information relevant to deepfake detection, but, again, a human operator is needed to excite that part of its knowledge base.”
This study indicates a potential future where fine-tuned LLMs could become a vital tool in media forensics, highlighting the continuous evolution and innovation within AI research.